第一部分 引入
1.概念
GPT:Generative Pre-Training 生成式的预训练、
2.工作机制
GPT也采用两阶段过程,第 一个阶段是利用语言模型进行预训练,第二阶段通过 Fine-tuning的模式解决下游任务。
3.GPT系列发布者
第二部分 GPT论文
1.摘要
(1)背景
大多数深度学习方法都需要大量的标注数据,在NLP领域中也是如此,但是标注数据毕竟是稀少的,大部分数据肯定还是非标注数据。
标注数据参考文章 : 类比机器学习,我们要教他认识一个苹果,你直接给它一张苹果的图片,它是完全不知道这是个啥玩意的。我们得先有苹果的图片,上面标注着“苹果”两个字,然后机器通过学习了大量的图片中的特征,这时候再给机器任意一张苹果的图片,它就能认出来了。
那碰到非标注数据该怎么办?
一种解决办法就是pre-training。 其实词向量就是一种pre-training技术,通过语言模型将文本转化为数字表示。
(2)方案
在优化期间使用任务感知输入转换来实现有效的传输,同时要求对模型架构进行最小的更改。
解释: 论文提出的主要是一种半监督的学习方法:非监督的预训练和监督的fine-tuning。 generative pre-training主要应用于无标记文本,在fine-tuning的时候使用了task-aware的方法,并且使模型的变化最小的前提下获得有效的转化。
(3)效果
模型在常识推理(Stories Cloze Test)上获得8.9%的绝对改善,在问答(RACE)上达到5.7%,在文本蕴涵(MultiNLI)上达到1.5%。
(1)词嵌入及其好处
略,详见课件。
(2)无监督学习
无监督学习是一种特殊的半监督学习,其目标是找到一个好的初始化点,而不是修改监督学习目标。可以使用语言建模目标对神经网络进行预训练,然后在监督下根据目标任务对其进行优化。
(3)辅助训练目标
增加辅助的无监督训练目标是半监督学习的另一种形式。用来来改进语义角色标记。
3.Framework
OpenAI 的系统分为两阶段,首先研究者以无监督的方式在大型数据集上训练一个 Transformer,使用语言建模作为训练信号,然后在小得多的模型上精调解决具体任务。
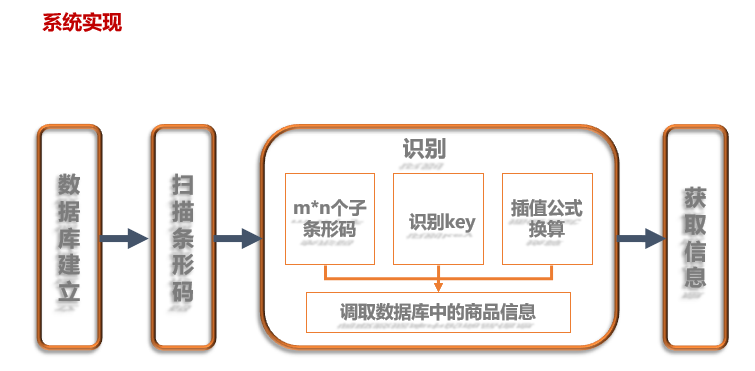
左图:Transfromer进行预训练。
右图:输入转换,用于对不同任务进行fine-tuning(精确调整)。我们将所有结构化输入转换成标记序列,然后由我们的预训练模型进行处理,然后是linear+softmax层。
(1)第一阶段: 非监督预训练
1)介绍
模型的一般方法是用语言模型去极大化极大似然函数。 在输入的文本上使用multi-head-self-attention(Bert中也有用到),之后使用包含位置信息的前馈神经网络,输出的是各个词的概率分布 。
2)特点(和ELMO相比)
首先,特征抽取器不是用的RNN,而是用的Transformer叠加的“自注意力机制” 构成的深度网络)。
评价:Transformer的特征抽取能力要强于RNN,这个选择是很明智的。
其次,GPT的预训练虽然仍然是以语言模型作为目标任务, 但是采用的是单向的语言模型。
“单向”的概念:GPT只采用Context-before(上文)来进行预测。
(2)第二阶段:监督微调
1)介绍
对前一个阶段训练出来的模型参数进行微调,以适应当前的监督型任务。 假设我们有带标签的数据集C, 经过我们的预训练模型在输入上的迭代之后,获得输出向量 ,然后经过线性层和softmax得到预测标签。
左图中
2)步骤
首先,对于下游任务来说,需要把任务的网络结构改成和GPT的网络结构一 样。
其次,利用第一步预训练好的参数初始化GPT的网络结构,把通过预训练学到的语言学知识引入到任务里来。
再次,用手头的任务去训练这个网络,对网络参数进行 Fine-tuning,使得这个网络更适合解决手头的问题。
(3)特殊任务的输入变换
对于特定的任务比如文本分类,我们能够直接使用上面的模型,因为文本分类的标签是确定的,正好对应论文的使用场景。由于文中的模型处理的是序列化的文本,对于问答系统或文本蕴含问题就需要手动修改文本格式、问题以及答案。
1)文本蕴含
用$连接前后两个文本,即前提p和假设h。
2)相似度
由于两个文本内部没有先后顺序,对此我们可以输入两个句子Text1$Text2和Text2$Text1,将结果用element-wise的方式相加起来,再放进线性输出层中。
3)问答系统和常识推理
对于这类问题一般有Context、Question和Answer{a1,a2,…,an},可以组合n个问答对(Context_i,Question_i,$,ai),获得n个输出,再将其通过linear层后softmax输出。
4.效果和不足之处
(1)效果
GPT的效果是非常令人惊艳的,在12个任务里,9个达到 了最好的效果,有些任务性能提升非常明显。
(2)不足之处
模型训练计算要求大: 以前许多用于NLP任务的方法都从头开始在单个GPU上训练相对较小的模型。我们的预培训步方需要8个GPU上进行1个月。
通过文本学习世界的局限性和片面性:最近的工作表明,仅通过文本就很难学习某些类型的信息,而其他工作表明,模型可以学习和利用数据分布中的偏差。
特征概括能力依然不足:尽管我们的方法可以提高各种任务的性能,但是当前的深度学习NLP模型仍然表现出令人惊讶和违反直觉的行为-尤其是在以系统,对抗或分布外的方式进行评估时。
GPT使用单向语言模型是个不好的选择,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果。比如阅读理解,在做任务的时候是可以允许同时看到上文和下 文一起做决策的,如果预训练时候不把单词的下文嵌入到 Word Embedding中,是很吃亏的,白白丢掉了很多信息。
5.GPT项目
第三部分 GPT2
1.GPT2模型简介
我们的模型称为GPT-2(是GPT的继承者),仅经过训练即可预测40GB的互联网文本中的下一个单词。由于我们担心该技术的恶意应用,因此我们不会发布经过训练的模型。作为负责任公开的一项实验,我们将发布一个供研究人员进行实验的小得多的模型以及一份技术论文。
2.GPT-2的训练目标
GPT-2是基于大型transformer的语言模型,具有15亿个参数,并在非常高质量的数据集上进行了训练800万个网页。根据文本中的所有先前单词,预测下一个单词。数据集的多样性使这个简单的目标包含了跨不同领域的许多任务的自然发生的演示。GPT-2是GPT的直接扩展,具有超过10倍的参数,并接受了超过10倍的数据量训练。
3.GPT-2的效果
GPT2显示了广泛的功能,包括生成具有空前质量的条件合成文本样本的能力,我们在模型中使用输入来填充模型并让其生成冗长的延续。此外,GPT-2优于其他在特定领域(如Wikipedia,新闻或书籍)上训练的语言模型,而无需使用这些特定于领域的训练数据集。在诸如答疑,阅读理解,总结和翻译之类的语言任务上,GPT-2开始使用原始文本来学习这些任务,而没有使用特定于任务的训练数据。尽管这些下游任务的得分远非最新,但它们表明,只要有足够的(未标记)数据和计算,这些任务就可以从无监督的技术中受益。
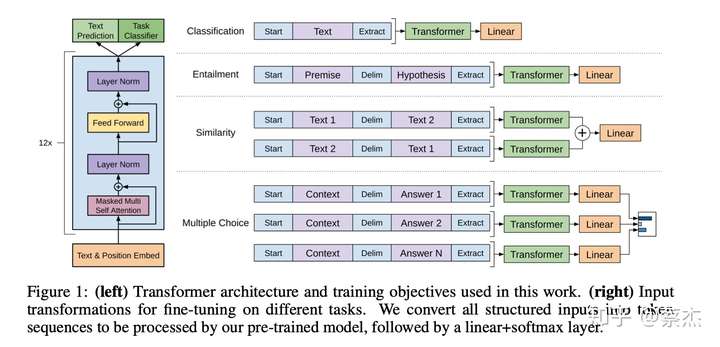
(1)答疑
(2)文本填充

(3)文章内容概括总结

(4)翻译
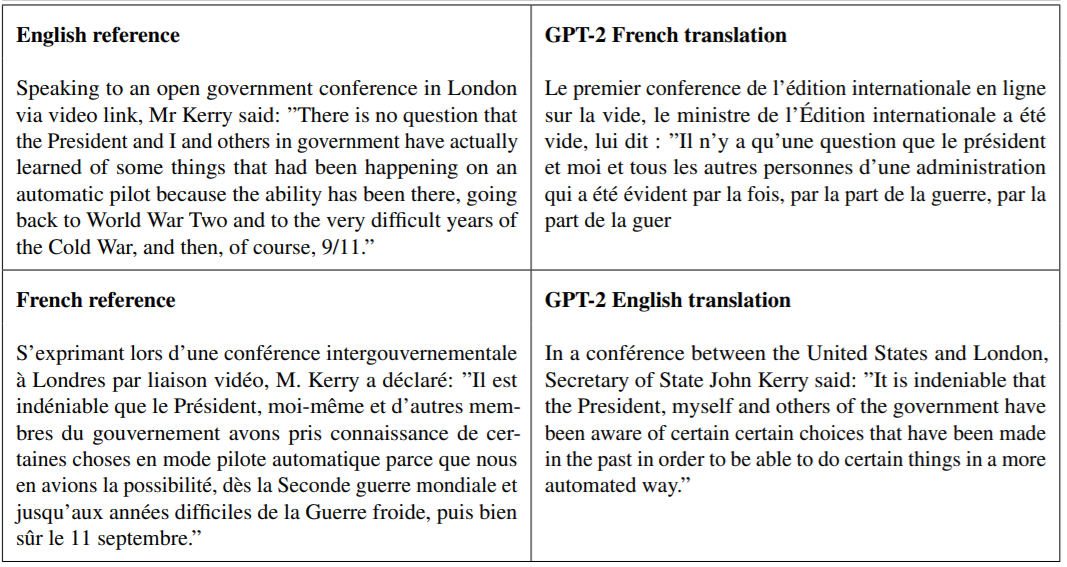
(5)阅读理解

第四部分 特别鸣谢
李芳芳,中南大学
蔡杰 ,北京大学:论文研读之OpenAI-Generative Pre-Training
- 文章链接: https://life-extension.github.io/2020/05/27/GPT技术初探/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!
-
安卓开发中遇到的坑坑洼洼
三月 1日, 2020
关键词:安卓开发,软件测试,错误排查。 大三下学期选修了十分重要的安卓开发课程,老师让我们编写编译书中的程序并完成书后的挑战练习。但是由于Android Studio的版本问题和gradle脚本以及主程序的命名与书中不同,这次编程还是...

-
螺旋上升,这就是我期盼的人生
一月 16日, 2021
还记得高中的时候,在政治课上学过一个“螺旋上升”理论,即“事物的发展,总是螺旋上升的”,而列宁也说过, “发展似乎是在重复以往的阶段,但它是以另一种方式重复,是在更高的基础上重复。” 回顾我这21年...
-
致即将逝去的21岁
一月 16日, 2021
在即将迎来22岁的日子,我想回顾一下21岁时的一些收获与遗憾。也当是把元旦没写完的文案补上一下。 在6岁的时候,我在爷爷家曾经画过一幅画,爷爷问我在画什么,我说,...
-
ACTF2020密码学部分writeup
六月 5日, 2020
编写的项目文件请参考项目链接。同时欢迎大家访问ACTF2020的所有赛题。喜欢的话请多多资瓷一下,给我们实验室的项目加个Star或者Fork,谢谢。 为了保护服务器的同时不给选手带来更多困难,密码学部分的交互题开了pow算力检测,我也...
-
通过python脚本自动插入汇编反调试代码
五月 20日, 2020
研究背景在之前OLLVM项目的研究过程中,我们发现反调试技术对反混淆脚本有一定的干扰作用,如果可以在OLLVM的中间代码中自动化插入反调试代码,那么就可以给OLLVM的代码混淆增加一层保障。 方案分析探讨多种方案以后,我认为最适合在汇...
-
答辩顺序抽签小程序
五月 14日, 2020
最近比较喜欢动手编写小程序和脚本。晚上有同学和我讨论对答辩队伍进行公平抽签的方案,所以打算编写一个很简单的小脚本,并做到尽量减少计算量。 脚本思路按照一定根据给各个队伍排序,然后初始化抽签序号池,每次随机获取池内的一个值,交给其中一支...
-
课堂记录小助手
五月 7日, 2020
作为一名课代表,我需要每天记录同学在QQ群的签到和回答问题情况。开始我是直接把记录复制到word里面手动提取有用的消息,最后我决定解放双手编写一个自动化处理脚本。 这个脚本需要一些什么功能呢?1.最基础的,就是从漫长的聊天记录中提取专...
-
基于门限方案的条形码保密及容错技术
四月 30日, 2020
关键词:门限方案,条形码保密,条形码容错,条形码认证与防伪造。 经历过初期两个小项目的探索,我们项目团队积累了一定的项目研究经验,在老师和16级学长的帮助下,我们把研究方向转到了门限方案的实际应用上。结合市面上用9张合并的条形码提高条...
-
2020新年原创脚本-其中的小把戏你清楚吗
四月 26日, 2020
关键词:随机数素数生成,新年祝福小程序。 脚本创作这是我在大年三十写的一个程序,当时我正准备去伯克利交流,但由于疫情的缘故,出国变数增大,所以我就打算通过随机数“未卜先知”。以下就是我的脚本: 12345678910111213141...
-
基于CRT的物流信息安全处理方案
四月 15日, 2020
关键词:中国剩余定理,密钥分发技术,隐私保护。 引言在2018年11月份的时候,段老师在密码学课上讲到了密钥分发协议,我当时就觉得这个协议很有意思也很有应用前景。后来老师还很主动地分享了一下它的idea,其中一部分就是有关物流单上的信...